
Intel on Tuesday launched the latest generation of its deep learning processors for training and inference, Habana Gaudi2 and Habana Greco, making AI more accessible and valuable to its data center customers. At its Intel Vision event, the chipmaker also shared details about its IPU and GPU portfolios, all aimed at business customers.
“AI is the engine of the data center,” Eitan Medina, COO of Habana Labs, Intel’s data center team focused on deep learning AI processor technologies, told reporters. . “It’s the largest and fastest growing application. But different customers use different blends for different applications.”
Diverse use cases explain Intel’s investment in a diversity of data center chips. Habana processors are designed for customers who require deep learning computing. The new Gaudi2 processor, for example, can improve visual modeling of applications used in autonomous vehicles, medical imaging and fault detection in manufacturing. Intel bought Habana Labs, an Israel-based programmable chipmaker, for around $2 billion in 2019.
The second generation Gaudi2 and Greco chips are both implemented in 7 nanometer technology, an improvement over the 16 nanometer for the first generation. They are made on Habana’s high-efficiency architecture.
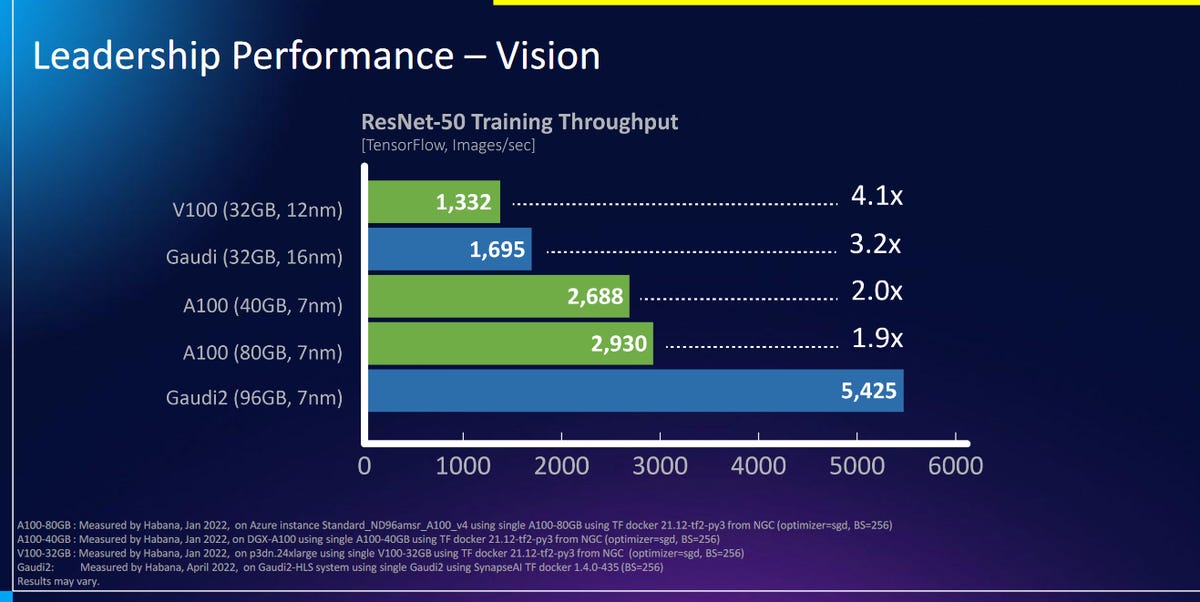
Intel said on Tuesday that Gaudi2 offers twice the training throughput of Nvidia’s A100-80GB GPU for the ResNet-50 computer vision model and the BERT natural language processing model.
Intel
“Compared to the A100 GPU, implemented in the same process node and roughly the same die size, Gaudi2 delivers clear leadership training performance, as evidenced by comparing apples to apples on key workloads “, Medina said in a statement. “This deep learning acceleration architecture is fundamentally more efficient and backed by a solid roadmap.”
Learn more about the Gaudi2:
- Compared to the first generation Gaudi, it offers up to 40% better price performance in the AWS cloud with Amazon EC2 DL1 instances and on-premises with the Supermicro X12 Gaudi training server.
- introduces an integrated media processing engine for compressed media and host subsystem offloading
- Gaudi2 triples the memory capacity in the enclosure from 32 GB to 96 GB of HBM2E at a bandwidth of 2.45 TB/sec
- integrates 24, on-chip, 100GbE RoCE RDMA NICs for scaling and scaling using standard Ethernet
Gaudi2 processors are now available for Habana customers. Habana has partnered with Supermicro to release the Supermicro Gaudi2 training server this year.
Meanwhile, the second-generation Greco inference chip will be available to select customers from the second half of this year.
Learn more about the second generation Greco:
- Includes boosted on-board memory, essentially getting 5x the bandwidth and pushing on-chip memory from 50MB to 120MB
- Adds decoding and media processing
- Offers a smaller form factor for compute efficiency: from dual-slot to single-slot FHFL
“Gaudi2 can help Intel customers train increasingly large and complex deep learning workloads with speed and efficiency, and we anticipate the inference efficiencies that Greco will bring,” said Sandra Rivera, executive vice president of Intel, in a statement.
Intel also on Tuesday unveiled an expanded roadmap for its infrastructure processing unit (IPU) portfolio. Intel originally built IPUs for cloud giants – hyperscalers like Google and Facebook – but it’s now expanding access.
Intel
Intel will ship two IPUs next year: Mount Evans, Intel’s first ASIC IPU, and Oak Springs Canyon, Intel’s second-generation FPGA IPU that will ship to Google and other service providers.
In 2023 and 2024, Intel plans to roll out its third-generation 400 GB IPUs, named Mount Morgan and Hot Springs Canyon. By 2025 and 2026, Intel plans to ship 800 GB of UIP to customers and partners.
Intel also shared details on its data center GPU, named Arctic Sound, on Tuesday. Designed for multimedia transcoding, visual graphics and inference in the cloud, Arctic Sound-M (ATS-M) is the industry’s first discrete GPU with an AV1 hardware encoder. It delivers performance targeting 150 trillion operations per second (TOPS). The ATS-M will be available in two form factors and more than 15 system designs from partners including Dell, Supermicro, Inspur and H3C. It will be launched in the third quarter of this year.